Visual Question Answering (VQA)
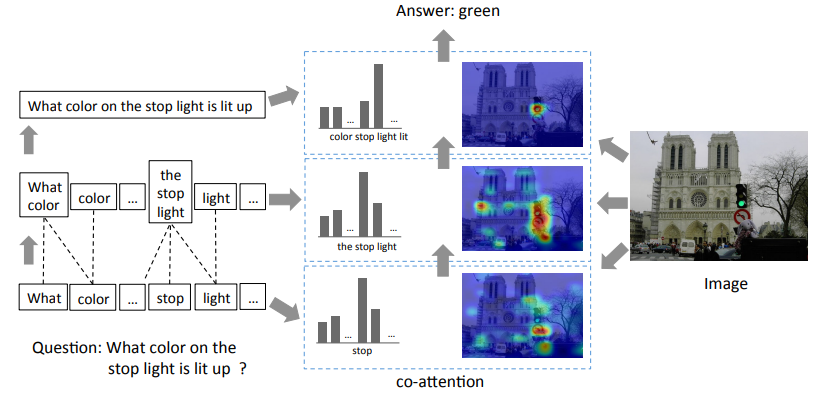 sourced from Lu et al. (2016).
sourced from Lu et al. (2016).
Overview
To correctly answer visual questions about an image, the machine needs to understand both the image and question. A model that can jointly reasons about image and question attention could improve the state-of-the-art on the VQA problem. So I decided to study the paper and experienced this novel mechanism by myself. In this repository only parallel co-attention mechanism which generates image and question attention simultaneously is implemented.
Architecture
- STEP 1: Extract image features from a pre-trained CNN (VGG19 is used here).
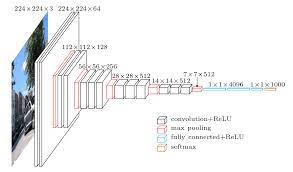
- STEP 2: Compute word embedding, phrase embedding and question embedding
- STEP 3: Calculate co-attended image and question features from all three levels (word, phrase, question)
- STEP 4: Use a multi-layer perceptron (MLP) to recursively encode the attention features
Dataset
I evaluate the proposed model on the VQA 2 dataset. The dataset contains 443 757 training questions, 214 354 validation questions, 447 793 testing questions, and a total of 6 581 110 question-answers pairs. There are three sub-categories according to answer-types including yes/no, number, and other. Each question has 10 free-response answers. The paper uses the top 1000 most frequent answers as the possible outputs. This set of answers covers 87.36% of the train+val answers. For testing, I train the model on VQA train+val and report the test-dev and test-standard results from the VQA evaluation server like in the paper.
Results
| Model | Yes/No | Number | Other | All |
| VGG | 66.61 | 31.39 | 33.74 | 47.02 |
| ResNet | 69.08 | 34.58 | 38.45 | 50.73 |
Some prediction answers on the test-standard:


